En 1948, Norbert Wiener publicó “Cybernetics or Control and Communication in the Animal and the Machine”, obra fundadora de la cibernética, definida como la “ciencia de los sistemas reguladores”.
En 1950, John von Neumann - famoso como diseñador de la arquitectura de los computadores - había inventado los “autómatas celulares”, programas de auto-reproducción de componentes a partir de instrucciones simples (ejemplo al lado). Una máquina de este tipo contruiría una copia exacta de sí misma y cada una de estas copias podría hacer lo mismo. von Neumann hizo una demostración con modelos físicos capaces de desplazarse por un almacén lleno de piezas y componentes entre los cuales cada máquina escogía los necesarios para construir una copia de sí misma. Posteriormente desarrolló un modelo más abstracto, equivalente a un tablero cuadriculado infinito.
Este mismo tema fue abordado por Alan Turing, uno de los “padres” de la inteligencia artificial, en un trabajo sobre la “morfogénesis”, que publicó en 1954, poco antes de su muerte. Turing puso en evidencia el fenómeno de la emergencia usando herramientas matemáticas, demostrando cómo un organismo complejo podía desarrollarse sin ninguna dirección o plan maestro, a partir de pocas instrucciones.
En 1959, Oliver Selfridge publicó un paper titulado “Pandemonium”, que introducía la metáfora de pequeños demonios para designar rutinas de computador destinadas a reconocer patrones y, de nivel en nivel, terminar reconociendo textos.
“¿Cómo enseñar a una máquina a reconocer letras o sonidos vocálicos, acordes menores, huellas digitales, en primera instancia? La respuesta le obligó a añadir otro nivel de demonios, y un mecanismo de retroalimentación a través del cual se clasificaran las apuestas de los distintos demonios. Este nivel inferior estaba compuesto de mini programas todavía menos sofisticados, entrenados para reconocer tan sólo rasgos físicos en bruto (o sonidos, en el caso del código Morse o de la línea hablada). Algunos demonios reconocían rectas paralelas; otros, perpendiculares. Algunos buscaban círculos; otros, puntos. Ninguno de estos rasgos estaba asociado a una letra particular; los demonios de la base eran como niños de dos años capaces de informar de que estaban en presencia de formas determinadas, pero no de percibirlas como letras o palabras.
Al usar estos demonios con un mínimo de datos, podría entrenarse al sistema para reconocer letras, sin «saber» con anticipación nada del alfabeto. La receta era relativamente simple: presentar la letra "b" a los demonios del nivel inferior, y ver cuáles responden y cuáles no. En el caso de la letra "b", los reconocedores de líneas verticales responderían junto con los reconocedores de círculos. Esos demonios del nivel inferior informarían a los reconocedores de letras de un eslabón superior en la cadena. Sobre la base de la información recabada por sus soldados, ese reconocedor arriesgaría una identidad de la letra. Después, esas apuestas serían clasificadas por el software. Si la apuesta es incorrecta, el software aprende a disociar a los soldados particulares de la letra en cuestión; si es correcta, fortalece la conexión entre los soldados y la letra.
Al principio, los resultados son erráticos; pero si se repite el proceso mil veces o diez mil, el sistema aprende a asociar grupos específicos de reconocedores de formas con letras específicas y pronto será capaz de traducir oraciones enteras con notable exactitud. El sistema no tiene concepciones predefinidas acerca de la forma de las letras: se le entrena para asociar letras con formas específicas en la fase de clasificación. ” (Johnson, pp.51-52)
Este es aún hoy el sistema que utilizan los sistemas de inteligencia artificial. Así, el artículo de Selfridge ha sido reconocido como la primera descripción de una aplicación informática con poder de emergencia.
En la década de 1960, John Holland, alumno de Norbert Wiener, siguió este modelo y le aplicó la lógica de la evolución darwiniana. Construyó así un código que llamó “algoritmo genético”, que imita la forma en que opera la selección natural para evaluar y reproducir las variaciones que logran más éxito en sus conductas. “Si se atraviesa un número suficiente de ciclos, se obtendrá la receta para obras maestras de ingeniería como el ojo humano, sin un auténtico ingeniero visible.” (Johnson, p.54)
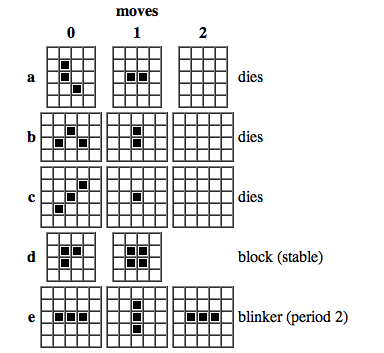
En 1970, el matemático británico John Horton Conway dió a conocer lo que llamó juego “Vida”, un autómata celular del tipo concebido por von Neumann, que es fácil jugar con fichas de dos colores en un tablero como el de ajedrez (pero preferiblemente más grande) o de programar en un computador. En él, se considera el entorno de cada casilla, formado por las ocho celdillas que la rodean. Cada célula tiene dos estados (vacía u ocupada) y las reglas de transición son las de nacimiento, supervivencia o muerte, lo cual depende de la condición de las células vecinas (ocupadas o vacías). Con diferentes configuraciones iniciales de dos o más células ocupadas, se pueden obtener numerosas figuras que se desplazan por el tablero hasta su extinción, su reproducción o la producción de figuras diferentes con su propia “vida”. Un gran número de combinaciones han sido estudiadas en los años siguientes (“deslizadores”, “cosechadoras”, “astronaves”, “colmenares”, etc.), descubriéndose que con los “deslizadores” (de solo 5 células) se podía realizar cualquier cómputo (aunque el método sería poco eficiente). En otras palabras, una configuración simple de unas pocas células puede -teóricamente- realizar todas las operaciones posibles para un computador.
A mediados de los años 80, dos profesores de la UCLA, David Jefferson y Chuck Taylor, diseñaron un conjunto de micro-programas que imitarían la forma en que las hormigas siguen un rastro, el que llamaron “Tracker”. No era una solución sino un conjunto aleatorio de posibles desplazamientos, con un sistema de retroalimentación y autocorrección que “premiaba” los mejores resultados, haciendo emerger así programas cada vez más competentes.
“Finalmente, las herramientas de la informática moderna habían avanzado hasta el punto de poder simular inteligencia emergente, ver cómo se desplegaba en la pantalla en tiempo real tal como Turing y Selfridge y Shannon lo habían soñado años atrás. Y fue muy acertado que Jefferson y Taylor hubieran elegido para la simulación justamente el organismo más famoso por su conducta emergente: la hormiga. Claro está que comenzaron (mi la forma más elemental de inteligencia -el rastreo de feromonas por el olfato-, pero las posibilidades que sugería el éxito del Tracker eran interminables. Se había logrado dominar las herramientas del software cu iei gente para modelar y comprender la evolución de la inteligencia emergente en los organismos del mundo real. En verdad, al ver evolucionar las hormigas virtuales en la pantalla de la computadora, al verlas aprender y adaptarse a sus entornos por sus propios medios, era inevitable preguntarse si acaso la división entre lo virtual y lo real no estaba volviéndose más y más borrosa.” (Johnson, p.57)
Poco después (1984) se fundó el Instituto Santa Fe, dedicado al estudio de la complejidad, y James Gleick publicó “Caos: la creación de una ciencia”. Luego aparecieron varios libros sobre el tema de la complejidad y trabajos sobre la “vida artificial”. El centro de todo era el concepto y la observación de un fenómeno ahora descubierto como universal: la autoorganización.

En 1987, en Los Alamos, Chris Langton organizó el 1º Encuentro sobre Vida Artificial, en que se trataron diversos tipos de sistemas dinámicos complejos (autómatas celulares, etc.). En 1989, el biólogo Tom Ray, de la Universidad de Delaware, creó el primer programa computacional de “vida artificial” – de simulación biológica –, a partir de una secuencia de sólo 80 instrucciones, llamado “Tierra”. A partir de meras reglas de mutación, se observa la aparición de parásitos que compiten con los “seres” legítimos y aparecen los típicos fenómenos de evolución de predadores, e incluso extinciones completas y resurgencias (¡sin interacción con otras especies ni con un medio ambiente!).
"Pauta nacida en lo informe: ésa es la belleza fundamental de la biología y su misterio básico. La vida succiona orden de un océano de desorden. Erwin Schrödinger, pionero de la teoría cuántica y uno de los físicos que efectuaron incursiones de aficionado en la especulación biológica, lo expresó así hace cuarenta años: un organismo vivo tiene el "asombroso don de concentrar una 'corriente de orden' en sí mismo y se libra de esa suerte de decaer en el caos atómico. En aquella época ni los matemáticos ni los físicos proporcionaron apoyo a la idea. No había instrumentos idóneos para analizar la irregularidad como elemento constitutivo de la vida. Ahora se dispone de ellos.

«La evolución es caos con realimentación», escribió Joseph Ford. El universo se compone de azar y disipación, sí. Pero el azar con dirección llega a producir complejidad asombrosa. Y, como Lorenz descubrió hace tanto tiempo, la disipación es agente de orden. «Dios juega a los dados con el universo», replica Ford a la célebre pregunta de Einstein. «Pero con dados cargados. Y el principal objetivo de la física actual es averiguar según qué reglas fueron cargados y cómo podremos utilizarlos para nuestros fines.»" (Gleick, p.314).
Referencias:
Gleick,J. (1988): “Caos: la creación de una ciencia”, Barcelona, Seix Barral.
Johnson, S. (2003): Sistemas emergentes, México, FCE.






.jpg)