Las comunicaciones digitales están cambiando la política y la economía. Pero un costo económico que poco se considera es el de la operación de esta tecnología, y menos aún su costo ecológico. Algo que la COP24 debería haber señalado.
El llamado de atención
De lo que más se ha hablado es del enorme gasto energético de la minería de criptomonedas.
"Según informes recientes, el consumo eléctrico de la red Bitcoin alcanza 14,54 terawatts-horas (TWh) anuales, y se estima que la cantidad de energía necesaria para procesar una transacción en la red Bitcoin es de 163 kWh (kilovatio-hora), equivalente al consumo eléctrico de 5 días de un hogar estadounidense." (Coincrispy, 21/9/2017). En diciembre 2017,
"la fiebre del Bitcoin ha desatado el consumo eléctrico de las poderosas computadoras utilizadas para “minar” bitcoins. Debido a esto, el consumo energético mundial en el último mes aumentó más del 30 por ciento." (
Concienciaeco, 15/1/2018)
Pero podría ser aún peor: según la plataforma británica Power Compare (que compara los precios de la energía), el consumo anual de electricidad estimado de Bitcoin se sitúa en los 29,05 TWh, el equivalente al 0,13 por ciento de las necesidades globales de electricidad del mundo. Si Bitcoin fuese un país, se ubicaría en el puesto 61 de los consumidores a nivel mundial. En el último mes, se estima que el consumo de electricidad por minar Bitcoin ha aumentado un 29.98%. ¡Si sigue aumentando a este ritmo, la minería de Bitcoin consumirá toda la electricidad del mundo para febrero de 2020! (Conectica, 23/11/2017).
Las mayores "granjas" de equipos que minan criptomonedas se encuentran en China y en Siberia. ¡En algunos casos, el calor despedido es utilizado para calentar hogares! Así, los rusos Ilya Frolov y Dmitry Tolmachyov construyeron una casa de unos 76 metros cuadrados en Irkutsk, e instalaron dos sistemas para minar bitcoins. El calor de las unidades de procesamiento calienta un líquido que luego se bombea por cañerías en el suelo. Tienen la intención de construir alrededor de 2.000 “criptocalentadores” para el año 2020 (Coincrispy, 4/11/2017). Competirán con la compañía rusa Comino que también creó un dispositivo de minería de Ethers que funciona como calefactor (Coincrispy, 14/10/2017).
Internet
Pero también hay que preguntar cuanta energía requiere Internet para operar los millones de servidores que necesita (100 millones en 2014 según RenewIT) y todos los otros equipos y qué representa toda esta actividad en relación al calentamiento global.
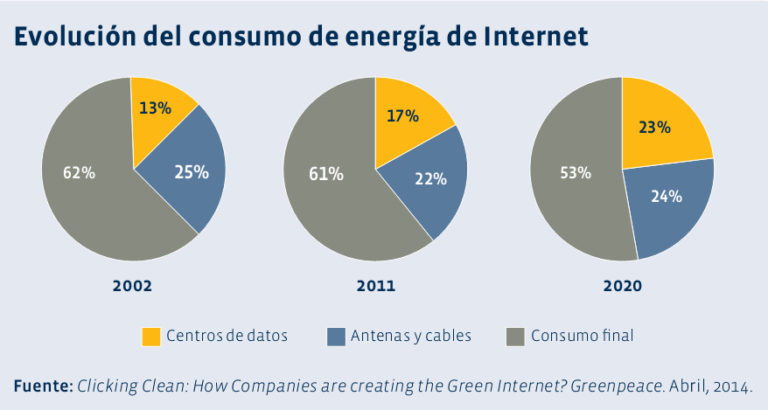
"En relación con las emisiones de GEI y a la afectación de la era digital en el cambio climático, el CEET y el prestigioso centro de investigación Bell Labs han calculado que el sector de las TIC e Internet produce 850 millones de toneladas de CO2 al año, cifra que se duplicará en 2020 (según uno de sus estudios). De las emisiones globales del sector de las TIC (año 2011), un 61% proviene del consumo final de nuestros dispositivos digitales y únicamente un 17% proviene de los citados data centers; aunque la previsión que hace el SMARTer 2020 Report es que este porcentaje llegue a un 23% el 2020." (Villagordo)
No todo es negativo sin embargo: “no se debe olvidar que Internet ayuda a mejorar la eficiencia de las industrias no digitales, que aún representan el 90% del consumo energético mundial” (Jon Koomey, citado por Villagordo) y, según el SMARTer 2020 Report, esta reducción significaría una reducción de emisiones de 7,8 Gt de CO2 que equivale a un 15% de las emisiones de sectores como el de la energía, la edificación, el transporte o el comercio (ibidem).
Los mayores consumidores son las granjas de servidores de grandes compañías como Google, Microsoft, Facebook, Amazon, etc. Las mayores granjas de servidores se encuentran en Tokio (130.000 m2), Chicago (102.000 m2), Dublín (51.000 m2), Gales (70.000 m2) y Miami (70.000 m2) (Villagordo).
No solo requieren electricidad para que funcionen los computadores sino tambien para refrigerarlos, por lo que muchas compañías han optado por tener instalaciones en los países nórdicos, para ahorrar en los sistemas de enfriamiento.
Microsoft, por su parte, empezó a instalar centros de cómputo bajo el mar, el Project Nautick. El primero, que tiene 12 racks con 864 servidores, ha sido instalado sobre una losa de roca en el fondo marino cerca de las Islas Orcadas de Escocia. Esta ubicación reduce su consumo de electricidad a apenas un cuarto de megavatio, utilizando energía 100% renovable de fuentes eólicas y solares de las Islas Orcadas (Xataka, 6/6/2018). De lo que nose habla es de la "colaboración" al recalentamiento de los océanos con el calor emitido.
Plataformas
Facebook, además de su instalación propia en Oregon, empleaba, en 2011, por lo menos nueve centros de datos de terceros en los EE.UU.. Requería en promedio hasta 6 megavatios para su funcionamiento, una cantidad que serviría para dar energía a más de 4.600 casas durante un mes.
Ese mismo año, Google tenía por lo menos 36 centros de datos en todo el mundo (la cantidad real es secreta). Tan sólo su centro de datos en Oregon emplea 103 megavatios, equivalente al gasto de 80 mil casas al mes. Pero desarrolló un algoritmo basado en aprendizaje de máquina que gestiona la refrigeración en varios de sus centros de datos de forma autónoma, logrando -en 2018- un ahorro de energía de alrededor del 40 %, dejando el gasto en refrigeración en 10 % del consumo total, Desde 2017 funciona 100% con energías renovables (
Ecoinventos, 18/9/2018). El centro de datos de Google en Chile obtiene su energía de la planta fotovoltaica El Romero Solar, de propiedad de Acciona Chile (
RevistaEI, 12/2/2018).
El centro de datos de Yahoo! de Lockport, Nueva York, utiliza el viento como una fuente natural de enfriamiento y electricidad que proviene de las cataratas de Niágara. Su centro de datos de Quincy es impulsado en 100% por energía hidroeléctrica. (Datos de 2011 de
Hipertextual, 20/4/2011).
Centros de datos
Hyperscale data centers 2017 (como Amazon, Apple, Facebook y Google)
Según AEM Sistemas, los Centros de Procesos de Datos consumen un 2% de la electricidad mundial, considerando Estados Unidos y Europa, y esta cantidad crece constantemente. La climatización que requiere un centro de datos mediano (con 15 o 20 Racks) aunque consume "solo" entre 5 y 10 kW para sus máquina, puede consumir otros 200 kW para las fuentes de alimentación ininterrumpidas, la iluminación y otros equipos auxiliares (
Aemsistemas, 10/2/2016).
"Un informe de 2016 del Laboratorio Nacional Lawrence Berkeley del Departamento de Energía de EE.UU. afirmaba que los centros de datos sólo en EE.UU. consumieron alrededor de 70 mil millones de kilovatios-hora en 2014, casi el 1.8 % del total de consumo de todo el país." (Ecoinventos, 18/9/2018).
"En un data center, aproximadamente el 50% de la energía se invierte en la carga de los sistemas informáticos. La otra mitad va a la infraestructura física del data center, que incluye equipos, sistemas de enfriamiento e iluminación. Toda la energía consumida por el data center termina desperdiciada como calor que se lanza a la atmósfera de forma continua." (
Certificadodeeficienciaenergetica.com, 26/7/2017)
"Se estima que un centro de datos grande puede consumir hasta 40 mil millones de kW/h anuales de energía, aproximadamente el consumo que genera una ciudad de 30.000 habitantes." (Boletín.com.mx, 14/9/2018)
Lamentablemente, "hoy en día la mayor parte consumen electricidad generada en plantas de carbón y centrales nucleares; por ejemplo, el 55,1% de la energía utilizada por Apple para sus servidores proviene del carbón, un 49,7% en el caso de IBM y un 39,4% en el caso de Facebook" (Villagordo).
Tanto los Estados Unidos han tomado medidas estableciendo normativas y programas de ayuda para desarrolar mejores prácticas, pero aún faltan más normas obligatorias (
Aemsistemas, 10/2/2016).
Otros equipos (y nuestro uso)
No olvidemos que las antenas de móvil y los dispositivos necesarios para acceder a Internet (PC, smartphones, routers, etc, repetidores de redes, etc.) tamién consumen grandes cantidades de electricidad y representan juntos 53% del consumo total correspondiente a internet y 8 a 10% del consumo energético mundial, según Clicking Clean, pudiendo llegar a 15% en 2025 según el Centre for Energy-Efficient Telecommunications (CEET) (Villagordo).
Consumo de componentes de internet:
Proyección de incremento total:
Todo lo que hacemos implica un gasto de energía, la emisión de calor y -dependiendo de los centros de datos - emisión de CO2. "El funcionamiento de nuestros dispositivos digitales, principalmente los teléfonos móviles y los tablets, representan el 20% de las emisiones directas asociadas a estos gadgets." El envío de un email implica la emisión de 4g/CO2, y de 50g/CO2 en el caso de contar con un adjunto pesado. Y lo peor es que los spams que se generan emiten 28,5 millones de toneladas de CO2, además de un total de 104.000 millones de horas para borrarlos (Villagordo).
¿Y cuanta energía y emisiones de CO2 está asociadas a la fabricación de los equipos y a su transporte?
"El ciclo de vida de un móvil, incluyendo los costes ecológicos de la producción, transporte, residuos, etc., y suponiendo una durabilidad de entre 3 y 5 años, -aunque en realidad se reponen antes-, genera el equivalente a 23,5 kg de CO2." Una fábrica de Beijing que emplea a más de 10.000 personas tenía unas emisiones de unas 21.500 toneladas de CO2 en 2010 (
Terra, 2010) [No encontramos datos más recientes.]
Otro efecto ambiental es el problema del reciclaje de los equipos dados de baja. En 2010, se calculaba que cada europeo producía entre 17 y 20 kg de resíduos de aparatos eléctricos y electrónicos (RAEE). Recordemos que estos equipos contienen plomo, mercurio, cadmio, arsénico, cromo hexavalente y retardadores de llama bromados (BFR) PBB y PBDE, todos tóxicos. ¡Una tonelada de teléfonos móviles genera unas 211 toneladas de estos residuos considerando la extracción, el procesado de los materiales que lo componen, la manufactura, el ensamblaje y el producto final! (
Terra, 2010)
El llamado de
Green Peace:
"Tech companies are regularly pumping out a new ‘must have’, creating a cycle of waste where billions of electronics are produced, sold, and thrown away. We need to change how we produce and consume to limit the damage we do to the Earth’s resources."
Electronic waste:
Referencias:
Greenpeace International (2009):
Switching on to Green Electronics.
Villagordo, A. (2017):
El impacto ambiental de la nube, Opcions.org 10/10/2017.